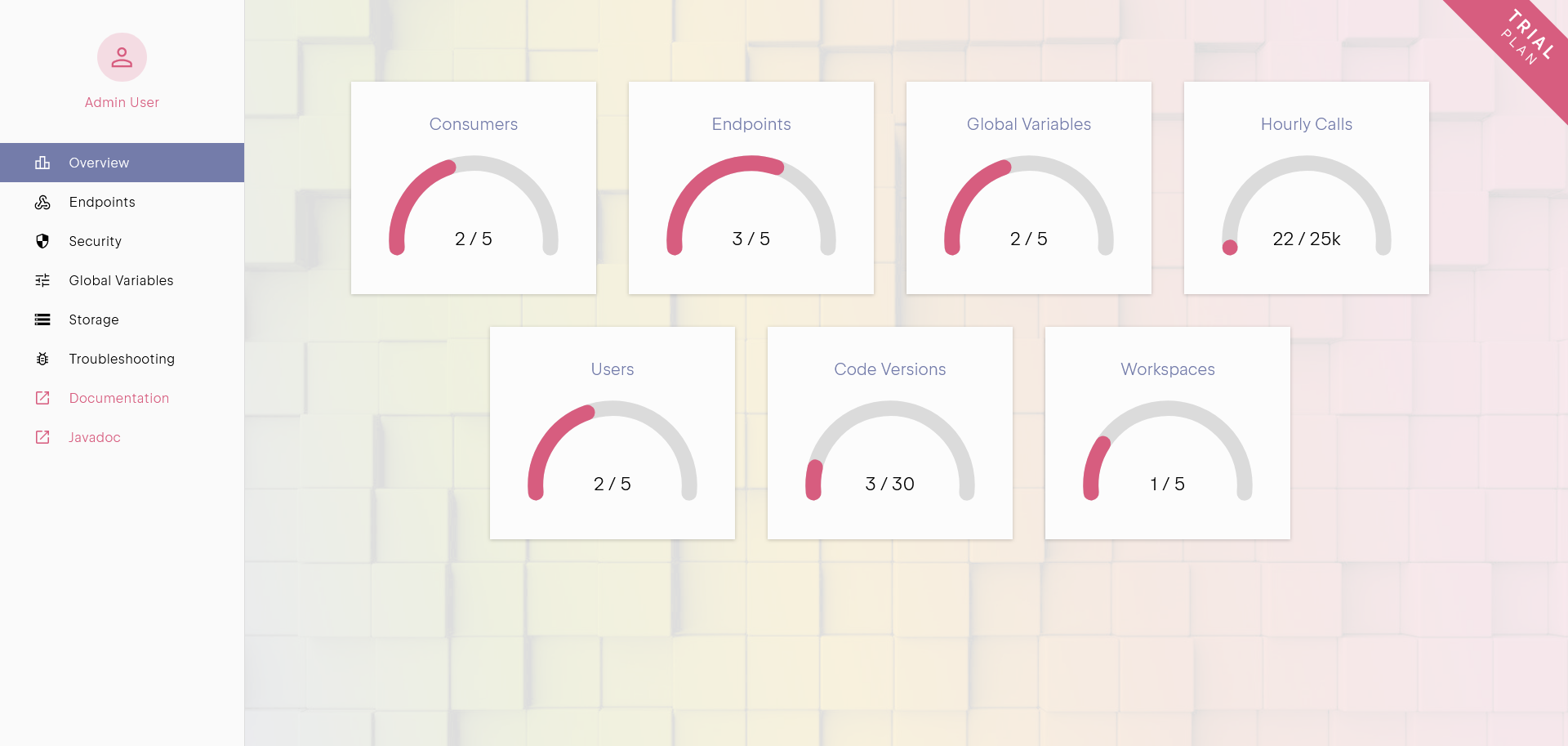
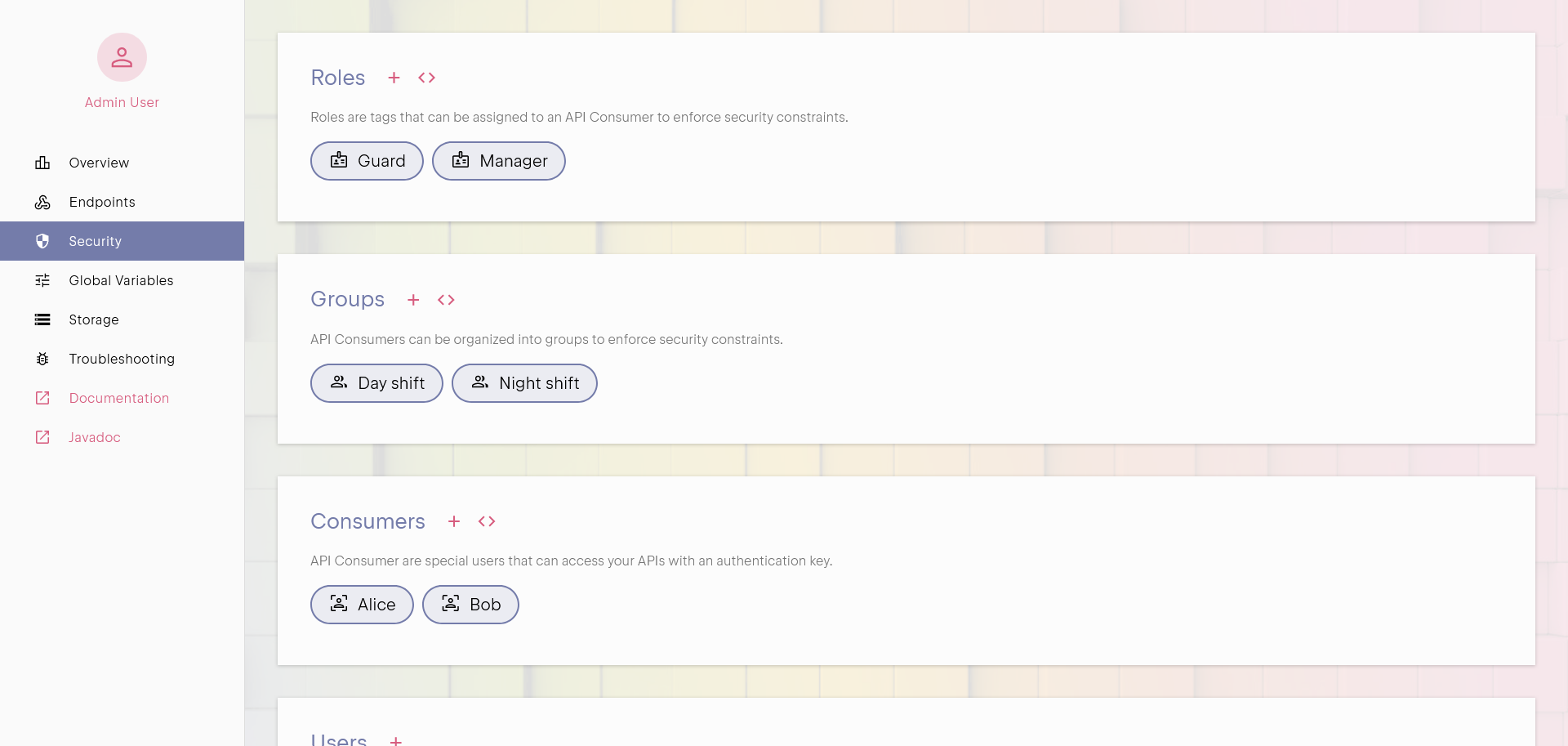
Getting Started
This section walks you through setting up your first API.
The approach might differ from what you're used to, but don't worry, you'll get the hang of it quickly.
Basic Concepts
Uniqorn provides a structured way to develop and deploy APIs while keeping things lightweight and flexible.
Let's introduce the fundamental principles of how your environment is organized and how APIs are managed.
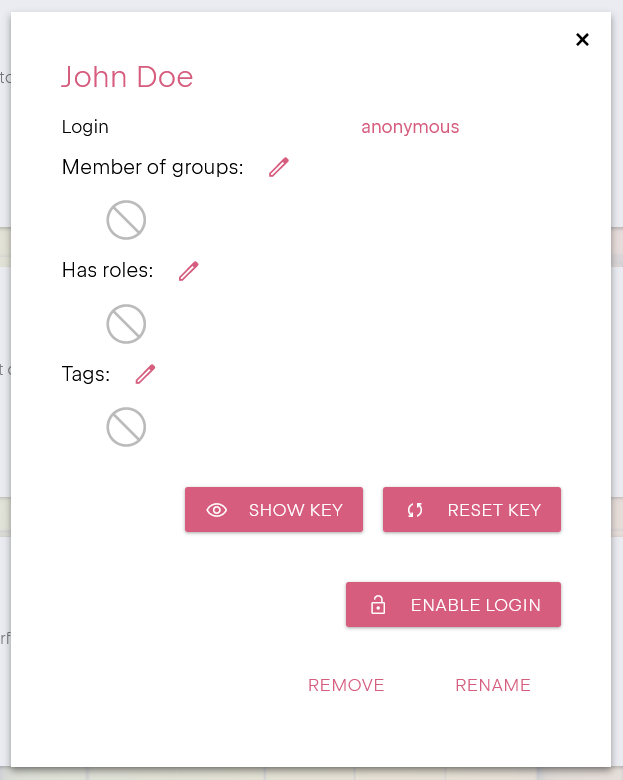
Instance & Authentication
When you subscribe to a plan, Uniqorn automatically provisions a dedicated instance for you. The details to
access this instance are sent via email, including the connection credentials. Depending on
your plan, your instance may run on a shared infrastructure (for trial and personal plans) or on fully
dedicated infrastructure (for team and enterprise plans).
We will never-ever ask for your credentials in any way, your privacy matters.
If you do not receive our emails,
please check your spam filter.
Be sure to always check the sender of the email to detect fraudulent phishing attempts.
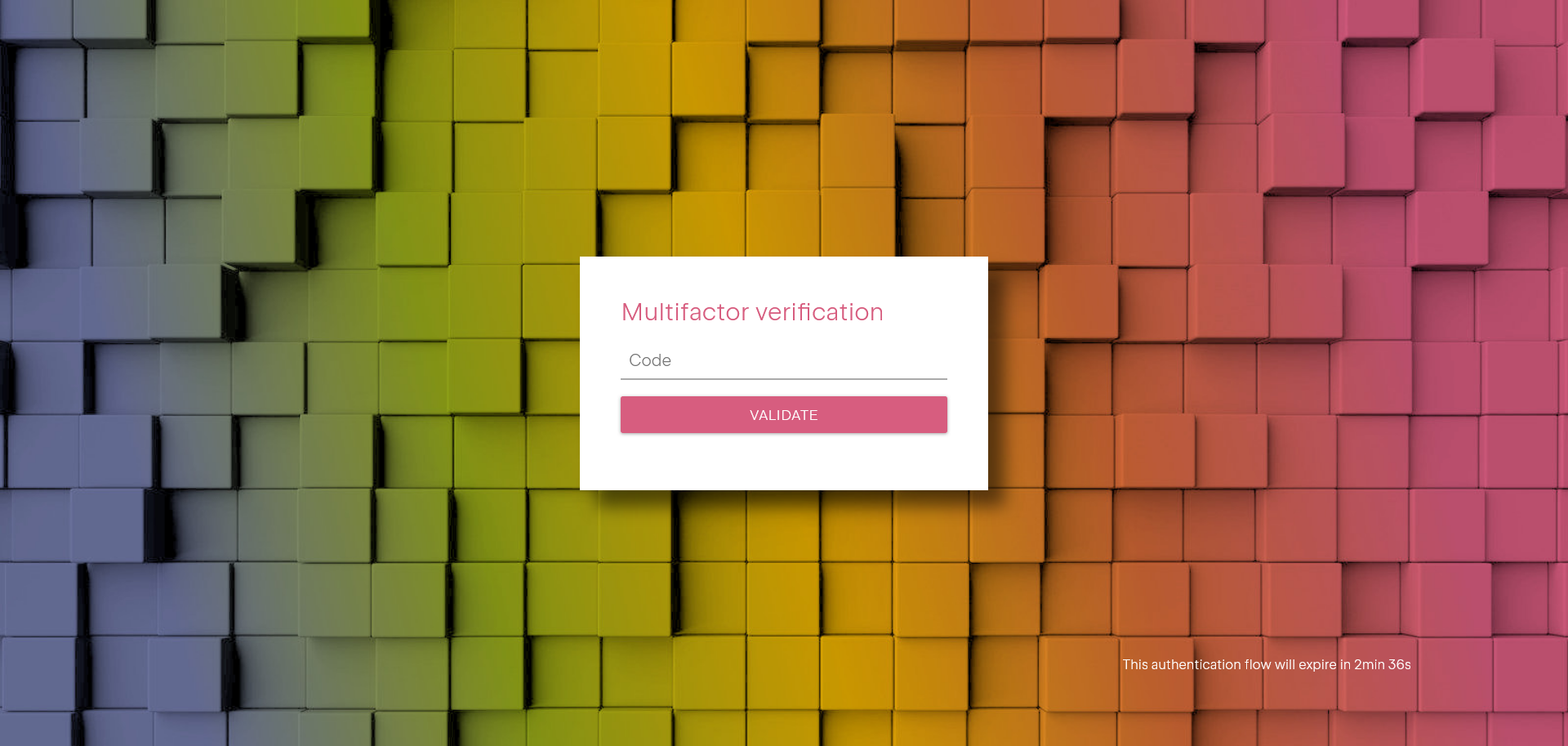
For security reasons, logging in requires Multi-Factor Authentication (MFA). You will need to configure an authenticator app
such as Google Authenticator, Authy, or any compatible alternative at your first connection. This extra layer of security ensures that access to
your environment is protected.
Workspaces & Organization
Once inside your personal instance, you can organize your work using workspaces. A workspace is a logical grouping of resources
that allows you to structure your APIs and services in a way that makes sense for your use case.
Workspaces can represent different projects, API versions, staging environments, or any other logical separation you need.
However, workspaces do not impose physical isolation. All APIs and resources within your instance share the same execution environment,
meaning they can interact with each other and have the possibility to produce side effects, for better or worst.
If complete separation is required, such as between development and production environments, it is recommended to use
separate instances (another subscription) rather than relying solely on workspaces.
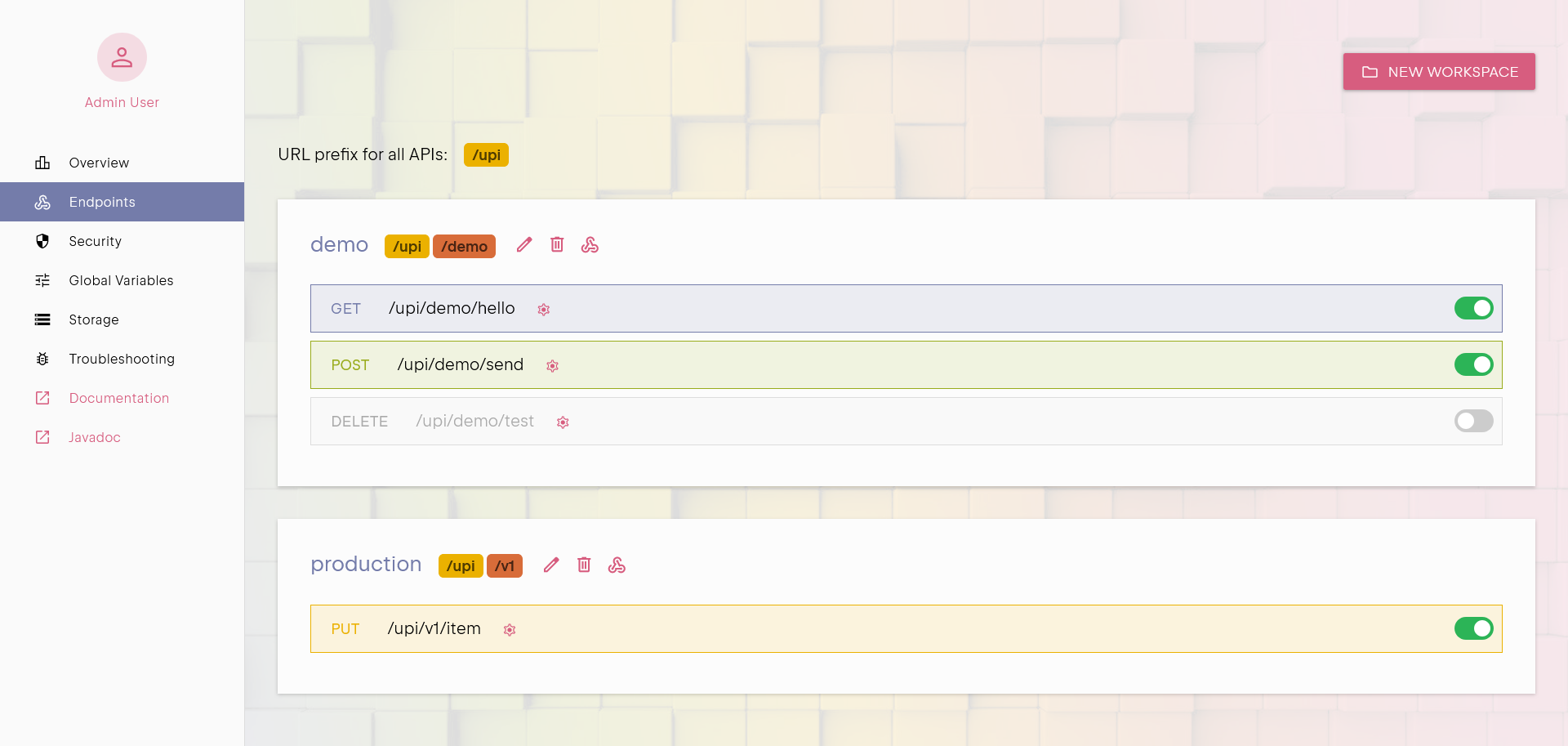
Configuring Resources & Deploying APIs
Within each workspace, you can configure various static resources and deploy API endpoints. Static resources include database connections,
storage locations, and other necessary components that support your APIs. These configurations remain available globally within your instance,
ensuring that APIs across different workspaces can access them as needed.
Deploying an API is a straightforward process. You have the option to:
- import an existing code file,
- write the code manually in the editor,
- or push changes via Git.
APIs can also be enabled or disabled on demand without deleting them, allowing for quick modifications and testing
without affecting the overall setup.
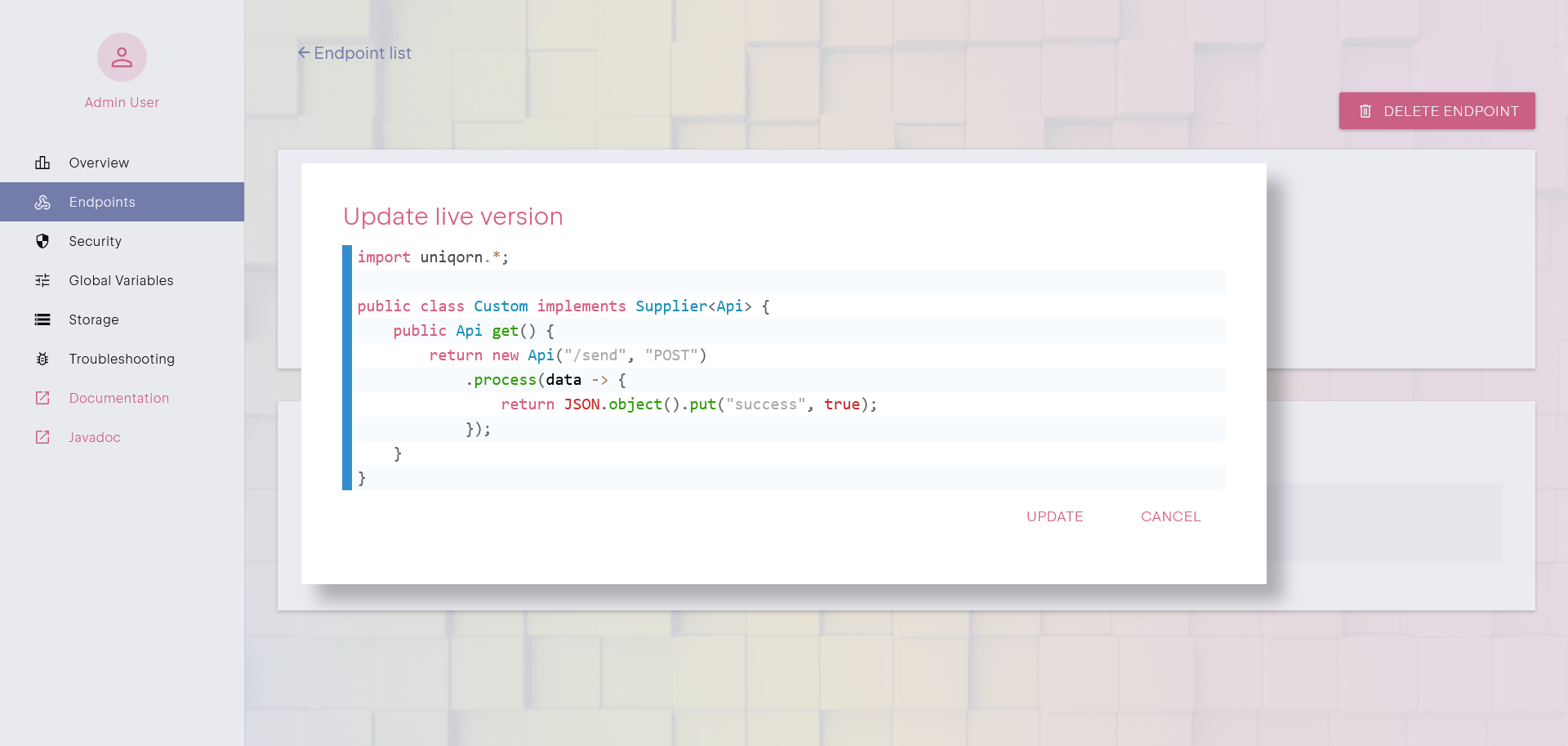
Live Code Execution
When you publish an API, the raw code is dynamically compiled and deployed instantly, requiring no additional build steps or restarts.
This ensures that changes take effect immediately without downtime. If an error occurs or an update needs to be made, you can simply modify
the endpoint and republish it. You can keep track of all modifications thanks to the built-in Git versioning.
It may happen that your instance is stuck because of infitinite loops or other mistakes. You have the possibility to trigger
a full instance restart to reset the system and perform the required changes.
If you encounter unrecoverable issues, please contact us.
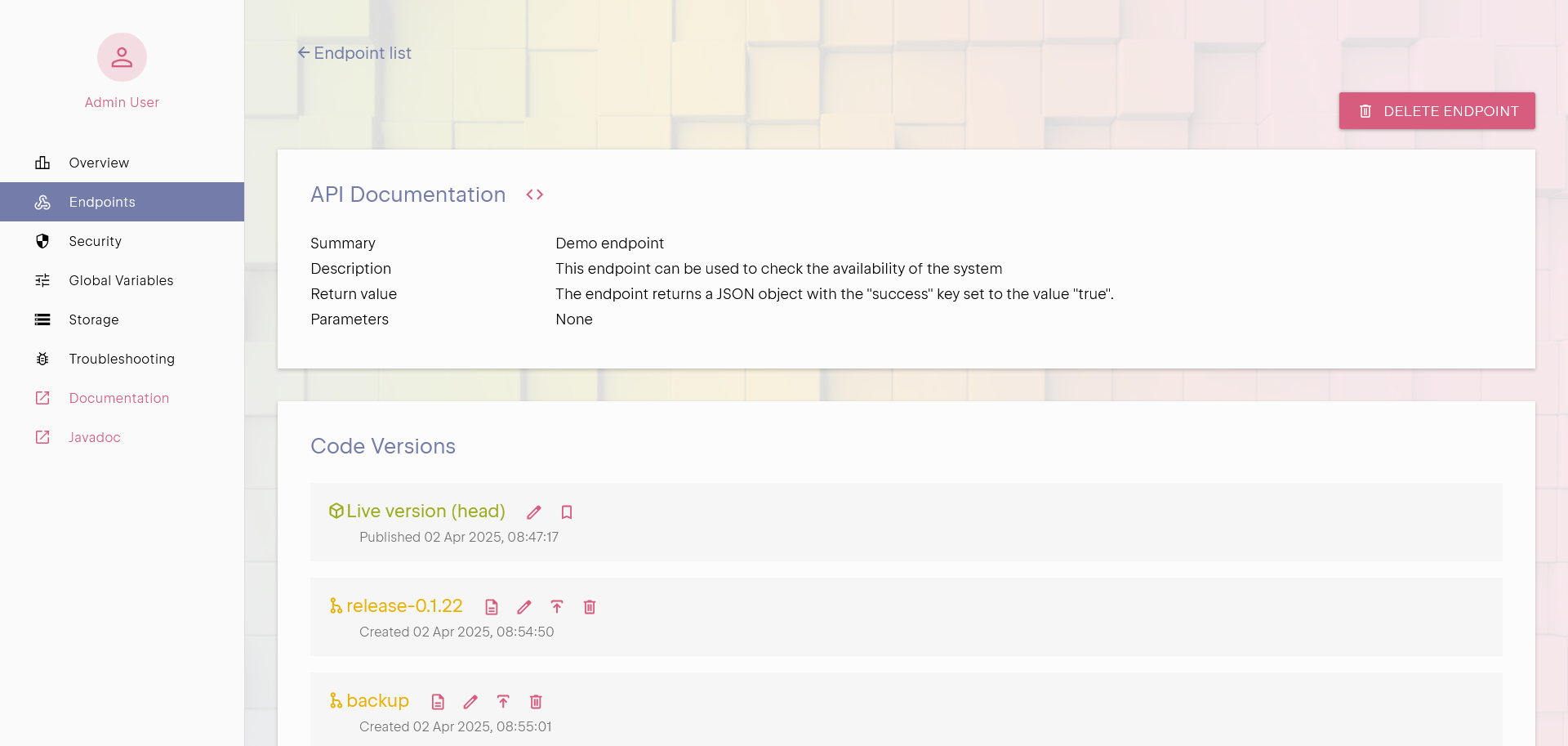
Versioning APIs
Uniqorn is backed by a full blown Git repository with a simple intuitive file structure. You can work as a team and track changes or use the panel
to perform changes, both methods are connected.
See API Versioning for more details.
Key Considerations
Since all APIs within an instance share the same execution environment, it is important to consider potential interactions and side effects.
Workspaces provide an organizational structure, but they do not enforce runtime isolation. If strict separation is required, using separate instances
for different environments is the recommended approach.
For managing API updates, the ability to quickly republish an endpoint simplifies error recovery, but there is no automated rollback. Users are
encouraged to tag stable versions and use standard Git practices to facilitate manual rollbacks if necessary. The entire Uniqorn system is also
API-based so it is fairly straightforward to setup a CI/CD system to automate the deployment process.
Code Structure
Let's see how Uniqorn APIs are structured and the different components involved in defining an endpoint. While this does not replace full
Javadoc documentation, it provides enough detail to help you understand the overall design and quickly get started.
import uniqorn.*;
public class Custom implements Supplier<Api> {
private AtomicInteger counter = new AtomicInteger(0);
public Api get() {
return new Api("/api/hello", "GET")
.parameter("name")
.description("This API will greet the user and return a counter value")
.allowUser("Bob")
.concurrency(2)
.process(data -> {
return JSON.object()
.put("hello", data.get("name"))
.put("counter", counter.incrementAndGet());
});
}
}
In the following sections we will dissect each part of the code to know more about how it works and implications.
Imports and Common Dependencies (mandatory)
Every API implementation starts with the uniqorn.* import, notice that there is no package defined, on purpose.
import uniqorn.*;
When you use this import, Uniqorn automatically includes commonly used Java packages and framework utilities.
This reduces boilerplate, so you don't have to manually import standard libraries like java.util.* unless you need something
beyond the default set.
Defining an API Supplier (mandatory)
Uniqorn follows a supplier-based approach for defining APIs. Instead of enforcing strict class naming conventions, you implement a
Supplier<Api> to return the actual API instance:
public class Custom implements Supplier<Api> {
public Api get() {
Unlike traditional Java frameworks, the class name is irrelevant, different APIs can use the same or different class names without conflict.
This structure allows you to define protected member variables, helper methods, or inner classes inside the API definition. These internal
elements remain isolated to the specific API and are not shared with other APIs.
public class Custom implements Supplier<Api> {
private AtomicInteger counter = new AtomicInteger(0);
public Api get() {
If you need to share data or functionality between multiple APIs, refer to the States & Sharing Data section of the documentation.
The API Endpoint (mandatory)
The API instance is created with a path and HTTP method:
return new Api("/api/test", "GET")
You have complete control over the path structure and HTTP method. Paths can include named parameters in curly brackets, such as
{name}, which will automatically be mapped to incoming request parameters.
You can use any HTTP method you like, although it must match exactly what the request contains in a case-sensitive fashion.
Declaring Parameters (optional)
Uniqorn supports fluent API design, allowing for cleaner and more readable code.
However, you are free to structure the code differently if you prefer.
To define input parameters, use:
.parameter("name", (value) -> value.size() > 0)
The framework automatically resolves parameters based on the incoming request type. Whether the request is GET,
POST, queryString, multipart, urlencoded, or json,
Uniqorn extracts the correct values seamlessly. Parameters are identified by name and can
optionally include a validation function to enforce constraints.
Adding Inline Documentation (optional)
For better organization and clarity, you can embed documentation directly into the API definition:
.summary("My first API")
.description("This API will greet the user if the name is provided")
.returns("A JSON object with the 'hello' property set with the provided name")
These descriptions help maintain clear, structured code without relying on external documentation tools.
The API documentation can be shared with your consumers and always reflect the latest deployed version.
Managing Security (optional)
Uniqorn provides built-in access control mechanisms, allowing you to allow or deny specific users, groups, or roles
at the API level. Access control elements (users, roles, groups) are managed centrally within your Uniqorn instance, ensuring consistency across all endpoints.
.allowRole("manager") .denyRole("customer")
.allowGroup("admins") .denyGroup("users")
.allowUser("Bob") .denyUser("Alice")
You can specify multiple roles, groups or users at once and use any combination of the above methods. The final granting decision is:
- If any deny clause matches, then access is denied.
- If any allow clause was specified but none matched, then access is denied.
- Otherwise (if an allow clause matches or there was no allow clause), access is granted.
Controlling Concurrency (optional)
Uniqorn allows you to limit how many requests can be processed in parallel for a specific API.
This ensures controlled execution and prevents excessive resource usage.
.concurrency(4)
By default, there is no concurrency limit, APIs can handle unlimited parallel requests as permitted by system resources.
Setting a hard limit on concurrency can be useful in cases where you need to prevent race conditions by ensuring an API is
accessed by only one or a few users at a time. If the API performs resource-intensive operations and should not be overloaded,
or if you want to throttle access to prevent excessive use, you can also define the concurrency limit.
For a strict single-user access, set .concurrency(1).
For unmetered access, do not specify the concurrency limit, or set .concurrency(-1)
When the limit is reached, additional requests wait for a running one to finish before they start. The order in
which waiting requests are admitted is not guaranteed. By default they wait as long as it takes; if you would rather a
request give up after a while, pass a maximum wait in milliseconds and a request that does not get a free slot in time
fails with an HTTP 503 response instead of waiting further:
.concurrency(4, 5000) // wait at most 5 seconds for a free slot
Defining API Logic (mandatory)
The core of the API is the process function, which defines the actual logic executed when the endpoint is called.
This function receives the incoming request parameters as a JSON object and should return a JSON object as a response.
.process(data -> {
return JSON.object()
.put("hello", data.get("name"));
});
The data parameter contains all resolved input parameters, regardless of whether they come from query parameters,
request bodies, or other sources. Uniqorn automatically handles data extraction and validation.
You can have access to the current authenticated user using .process((data, user) -> {}) if needed.
Restrictions
Code restrictions apply only if you do not have a dedicated environment. Team and Enterprise
plans do not have code restrictions.
To ensure runtime stability and security, Uniqorn enforces a set of restrictions on the code you deploy. The system
rejects the deployment if any belong to a restricted class or package:
HTTP/1.1 422 Unprocessable Entity
Content-Type: application/json
{
"error": {
"code": 422,
"message": "Use of restricted type: java.lang.Runtime"
}
}
Use Storage, Database and the Api helpers rather than
raw Java for storage, data and network access. The following capabilities are restricted:
| Restricted classes & packages |
|---|
| Reflection & dynamic dispatch |
java.lang.reflect.* java.lang.ClassLoader java.util.ServiceLoader
java.lang.Module
|
| Native & low-level access |
sun.* jdk.* java.lang.foreign.* java.lang.instrument.*
java.lang.SecurityManager java.security.AccessController
|
| Runtime & process control |
java.lang.Runtime java.lang.Process java.lang.ProcessBuilder java.lang.ProcessHandle
|
| File system access |
java.io.File java.io.FileInputStream java.io.FileOutputStream java.io.RandomAccessFile java.nio.file.* java.nio.channels.*
|
| Network access |
java.net.*
|
| Scripting & code execution |
javax.script.* javax.tools.* org.graalvm.*
|
| Serialization |
java.io.ObjectInputStream java.io.ObjectOutputStream java.io.Serializable java.io.Externalizable
|
| JVM & framework internals |
java.lang.management.* java.lang.module.* aeonics.manager.* aeonics.template.* aeonics.jit.* aeonics.entity.Registry aeonics.entity.Entity aeonics.Plugin
|
API Versioning
Uniqorn exposes native Git as the single source of truth for all your API code. Each instance behaves as a Git remote.
You push Java source files, the server compiles them, and the updated endpoints go live immediately.
This mechanism aligns with standard development practice. You work with Git as usual, and the platform takes care of build and deploy on
every push.
You are not required to use Git, you can update your endpoints in the panel by editing the code directly or dropping a file.
Every modification performed manually via the panel implicitly creates a Git commit in the main branch,
so both approaches are compatible and work transparently.
Enable Git Access
Each Uniqorn instance acts as a Git remote endpoint accessible through https. In order to connect, you must use your login as username,
and a special git access token as password. You can manage, revoke or rotate the access tokens in the panel.
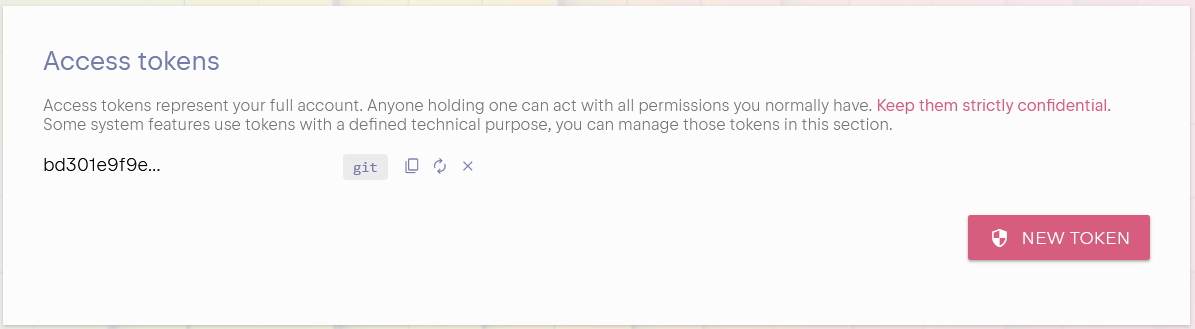
You can then clone the repository. The location is always the host name followed by /git/uniqorn:
$ git clone https://demo.live.uniqorn.dev/git/uniqorn
Your Git client must support the multi_ack_detailed, no-done, report-status,
and side-band-64k capabilities.
This is usually the case in most client tools.
Git File Structure
The file structure of the repository is fixed, the top level src directory is where all code must go.
Then, each workspace has its own directory. And finally the java code file.
repo/
├── src/
│ ├── workspaceA/
│ │ ├── endpoint1.java
│ │ └── endpoint2.java
│ ├── workspaceB/
│ │ └── reports.java
│ └── workspaceC/
│ ├── user_create.java
│ └── user_delete.java
└── www/
├── index.html
├── style.css
└── images/
└── logo.png
The www/ directory holds static web assets such as HTML, CSS, JS, images, and other files.
Files pushed to www/ are automatically extracted and served as static content.
See the Static Assets section below for details.
The workspace name can only contain a-z A-Z 0-9 -_. characters. No spaces, no special characters, no other subdirectories.
Remember that the workspace name is used as the url prefix for your endpoints.
Each terminal file represents one endpoint. The filename is irrelevant except for its .java extension.
The code inside determines the endpoint url.
Each file is standalone and independent.
You cannot import another custom class or reference code in another file. Each Uniqorn API is standalone and lives in its own code file
independently of other APIs. If needed, look at States & Sharing Data or how to
Chain Endpoints.
Updating endpoints
Every push on the main branch that changes a file triggers an automatic rebuild and redeploy of that endpoint.
Only the main branch is considered, other branches are accepted but not compiled.
When pushing changes, the server returns structured deployment feedback:
$ git push origin main
Enumerating objects: 9, done.
Counting objects: 100% (9/9), done.
Delta compression using up to 8 threads
Compressing objects: 100% (5/5), done.
Writing objects: 100% (5/5), 448 bytes | 448.00 KiB/s, done.
Total 5 (delta 1), reused 0 (delta 0), pack-reused 0
remote: [@Uniqorn] {"file": "/src/demo/hello.java", "error": null, "uri": "GET /upi/demo/hello", "status": "updated", "info": null}
remote: ---------------
remote: Done: created=0 updated=1 removed=0 ignored=0 error=0 in 152ms
remote: ---------------
To https://demo.live.uniqorn.dev/git
717c0ba..2da732c main -> main
- The
[@Uniqorn] section can be used by automation tools to parse the JSON output and get the status of the operation.
- The information between
--------------- is for humans, telling you how things went.
When pushing multiple files or multiple changes at once, each file is compiled independently and each produce one [@Uniqorn] output line.
Files are compiled and deployed independently, not as a batch. One may succeed while another fails.
Compilation errors
If a compilation error occurs, it is displayed during the push output:
remote: [@Uniqorn] {"file": "/src/demo/hello.java", "error": "Error at line 10: ';' expected", "uri": null, "status": "error", "info": null}
remote: ---------------
remote: /src/demo/hello.java - Error at line 10: ';' expected
remote: Done: created=0 updated=0 removed=0 ignored=0 error=1 in 51ms
remote: ---------------
If you were pushing a new endpoint, it is not deployed but the commit is stored normally in Git.
You will have to fix the issue and push a modified version.
If you were updating an existing endpoint, the new version is not deployed, although stored in Git normally,
and the previous version stays live.
You will have to fix the issue and push again to deploy the new version.
If your Uniqorn instance reboots, all endpoints are recompiled fresh from the latest Git head.
If those contain an error, then they are not deployed. No previous version available in this case.
Static Assets
In addition to Java API endpoints, Uniqorn can serve static files such as HTML pages, stylesheets, scripts, and images.
Place them in the www/ directory of your Git repository.
On every push, files under www/ are automatically extracted and served as static content from your instance.
Deleting a file from www/ removes it from the server.
repo/
└── www/
├── index.html
├── css/
│ └── style.css
└── images/
└── logo.png
This gives you full control over the frontend of your instance. Everything served from the root is yours to define,
from the landing page to the smallest asset.
A default index.html page is created automatically when your instance is provisioned. You can replace it by pushing your own.
Routing
For static assets, incoming requests are matched against the www/ directory using the following rules, in order:
- If the url matches a file, that file is served as-is.
- If the url omits the
.html extension and a matching [name].html file exists, it is served. This gives you clean,
pretty urls.
- If the url matches a directory it will resolve automatically to the nested
index.html file. /docs/ resolves to
/docs/index.html.
Reserved paths
You control everything except three reserved prefixes, which cannot be overridden:
/panel is for the management interface./oauth is for authorization and login./ae is for the frontend libraries. You can reuse them from your own pages, but you cannot modify them.
Custom 404
To customize what visitors see when a url matches nothing, place a 404.html page at the root of www/.
It is served whenever no file, pretty url, or directory index matches the request.
The push output reports static asset operations with the status extracted (for added or updated files) or removed (for deleted files):
remote: [@Uniqorn] {"file": "/www/index.html", "uri": null, "status": "extracted", "error": null, "info": null}
remote: [@Uniqorn] {"file": "/www/old-page.html", "uri": null, "status": "removed", "error": null, "info": null}
Static assets share the same storage quota as your instance. Large files count toward your storage limits.
Troubleshooting
When working with live APIs running on a server, traditional debugging tools like an IDE's debugger are not an option.
Instead, you need real-time insights into your API's execution flow, errors, and performance. The system provides a built-in
management interface that allows you to log messages, inspect runtime variables, analyze call stacks, and monitor performance
metrics, all without disrupting the running application.
This section covers the three primary ways to troubleshoot your API: Logging, Debugging, and Metrics.
Each of these tools serves a distinct purpose, helping you diagnose issues efficiently in a live environment.
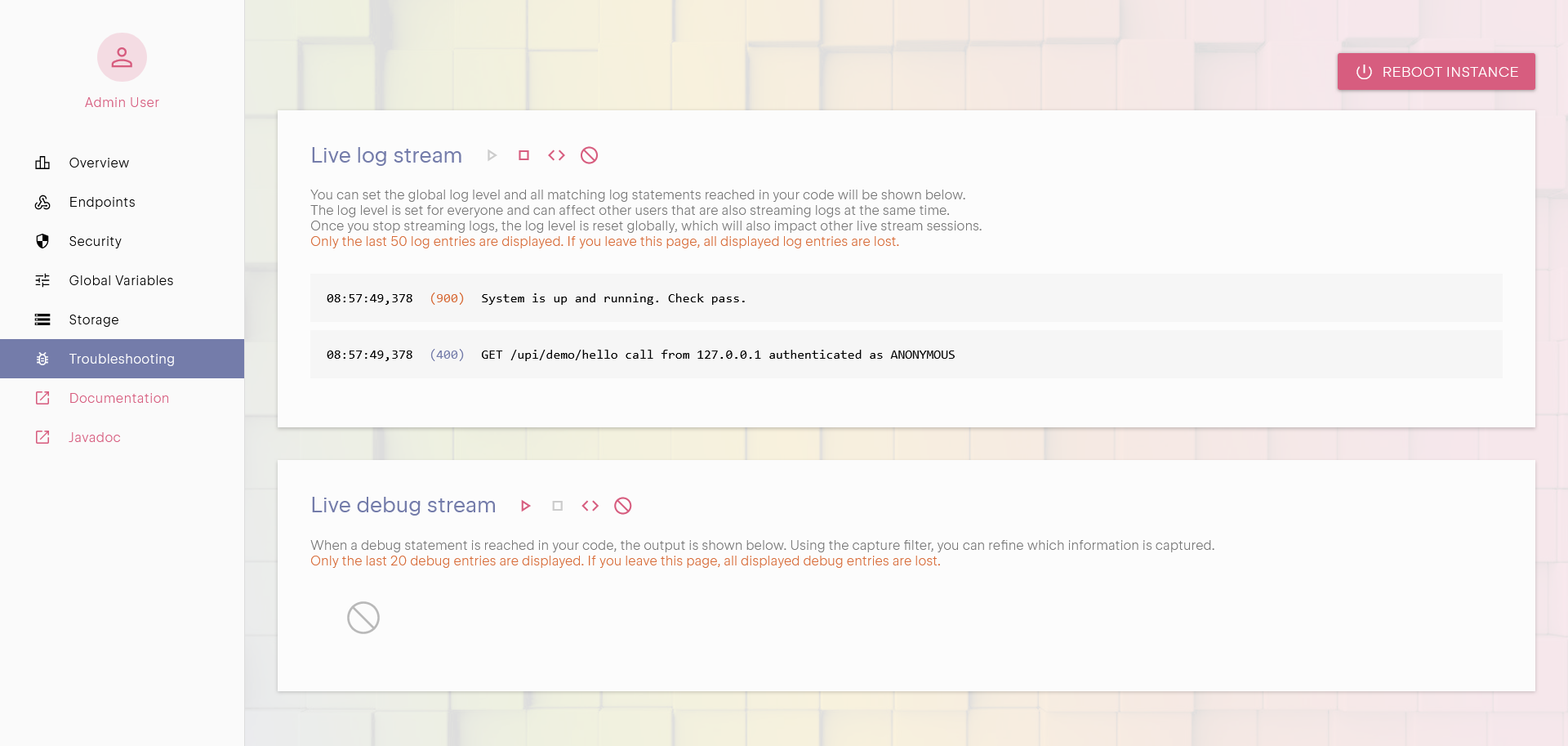
Logging
Logging is the simplest and most effective way to track what your API is doing. By writing logs, you create a live record of
execution flow, errors, and important state changes. These logs can be visualized directly from the management interface, allowing
you to monitor real-time behavior without modifying the API's response. Proper logging helps you understand what happened before
an error occurred and provides essential context for troubleshooting unexpected behavior.
Logs are streamed live through a WebSocket connection. You can visualize it in the management interface or consume it from any
compatible log management system.
Logging API
The Api class exposes 2 methods to record logs:
Api.log(int level, String message, Object...data);
Api.log(int level, Exception error);
Uniqorn logging uses a level-based system where the severity of a log entry ranges between 0 (detailed logs) and 1000 (critical issues).
Messages below the configured log level are ignored, ensuring that only relevant logs appear when debugging production environments.
Reference values for the log level are:
- 1000 (severe): Indicates a serious failure that requires immediate attention. This level is used for unrecoverable errors, such as system
crashes, database corruption, or data loss. Developers can use this level for business-critical failures, like failed financial transactions or security breaches.
- 900 (warning): Represents errors that do not halt execution but may lead to problems. This includes degraded performance, deprecated API usage,
or excessive resource consumption. Business logic may use this for cases like failed authentication attempts or temporary service disruptions.
- 800 (info): Logs normal system behavior, such as API start-up, shutdown, or important state changes. This level is useful for business events,
such as successful user logins, purchases, or account updates.
- 700 (config): Logs configuration-related events, such as loaded settings, environment variables, or changes in runtime behavior.
Useful for tracking how the system is initialized and whether any dynamic configuration updates occur.
- 500 (fine): A more detailed debugging level that provides insights into the general execution path of the application. Useful for tracking
function calls, loop iterations, or performance markers.
- 400 (finer): Logs finer details of execution, such as parameter values, cache hits/misses, or database query execution times. Useful
for troubleshooting performance bottlenecks.
- 300 (finest): Logs the most granular details, usually for deep troubleshooting. This level is used to trace function arguments,
individual computations, or low-level operations.
Logging levels are not restricted to the predefined reference values, you can use any intermediate level to fine-tune log granularity according to your needs.
For instance, setting a custom level like 450 allows you to log messages that fall between "finer" and "fine" without affecting lower or higher severity logs.
However, it is important to consider that every log operation incurs a small processing overhead, even if the message is ultimately filtered out by the log
level settings. While this impact is negligible for occasional logs, excessive logging can slow down API performance. To maintain efficiency, it is recommended
to remove verbose logging or troubleshooting logs unless they are strictly necessary.
If a log message contains {} placeholders, they will be dynamically replaced by the provided data arguments.
If more data is provided than placeholders, the extra values are ignored.
Api.log(800, "System activated"); // Simple log message
Api.log(500, "User {} has logged in", userId); // Log message with parameter injection
try { ... }
catch(Exception error) {
Api.log(900, error); // Log error details with the stack trace
}
{"date": 1741425960834, "level": 800, "type": "uniqorn.Api", "message": "System activated"}
{"date": 1741425960849, "level": 500, "type": "uniqorn.Api", "message": "User 41ae9da2-a875558911263000 has logged in"}
{"date": 1741426369953, "level": 900, "type": "uniqorn.Api", "message": "java.lang.Exception: Invalid data
at _m_1907317704888500_//_m_1907317704888500_.Custom.lambda$get$0(Custom.java:8)
at Loader-uniqorn/uniqorn/uniqorn.Api.lambda$process$1(Api.java:136)
at Loader-uniqorn/uniqorn/local.Endpoints.lambda$static$0(Endpoints.java:121)"}
Debugging
Since attaching an interactive debugger is not possible in a serverless context, debugging in Uniqorn relies on live variable inspection and call stack tracing.
The management interface allows you to visualize of your API's state at specific execution points, displaying variable values
and execution history. This method provides a practical alternative to stepping through execution as you would in a local debugger.
When an error occurs or unexpected behavior is encountered, logging alone may not be sufficient. Debugging allows you to capture variable states
and the call stack at any execution point, offering deeper insights into your API's behavior without modifying log levels.
Debug API
The Api class offers one method to expose debug information:
Api.debug(String key, Object...data);
Each debug entry is assigned a tag, which allows filtering and categorization in the management interface. As the number of debug points grows,
identifying which output corresponds to which line can become tedious, hence, tagging each log entry helps quickly locate relevant
sections of your code.
Debugging automatically captures:
- The stack trace at the time of execution, with some non-essential entries automatically removed to focus on relevant parts.
- Provided variables, converted to a human-readable JSON format for easier inspection.
Debug information is streamed live through a WebSocket connection, making it accessible in the management interface
or from any compatible system.
new Api("/api/test", "GET")
.process(data -> {
...
Api.debug("Checkpoint A", userId, userName);
...
});
{
"stack": [
"_m_1907317704888500_//_m_1907317704888500_.Custom.lambda$get$0(Custom.java:8)",
"Loader-uniqorn/uniqorn/uniqorn.Api.lambda$process$1(Api.java:136)",
"Loader-uniqorn/uniqorn/local.Endpoints.lambda$static$0(Endpoints.java:121)"
],
"values": [
8755589,
"John Doe"
]
}
This output allows you to trace execution flow and inspect the values of key variables in real time, making it a powerful
tool for diagnosing issues without disrupting the running API.
Debugging is a costly operation, do not forget to comment or remove debug code when your API is ready.
Metrics
Monitoring and performance troubleshooting requires more than just error logs, it demands an understanding of how the system is behaving over time.
Built-in metrics provide insights into API request rates, execution times, and error frequencies. These metrics help
identify performance bottlenecks, unexpected spikes in traffic, and potential scaling issues. By interpreting these real-time statistics,
you can optimize your API's performance and ensure it runs efficiently under varying loads.
In addition to built-in metrics, you can declare custom counters that can track your own indicators.
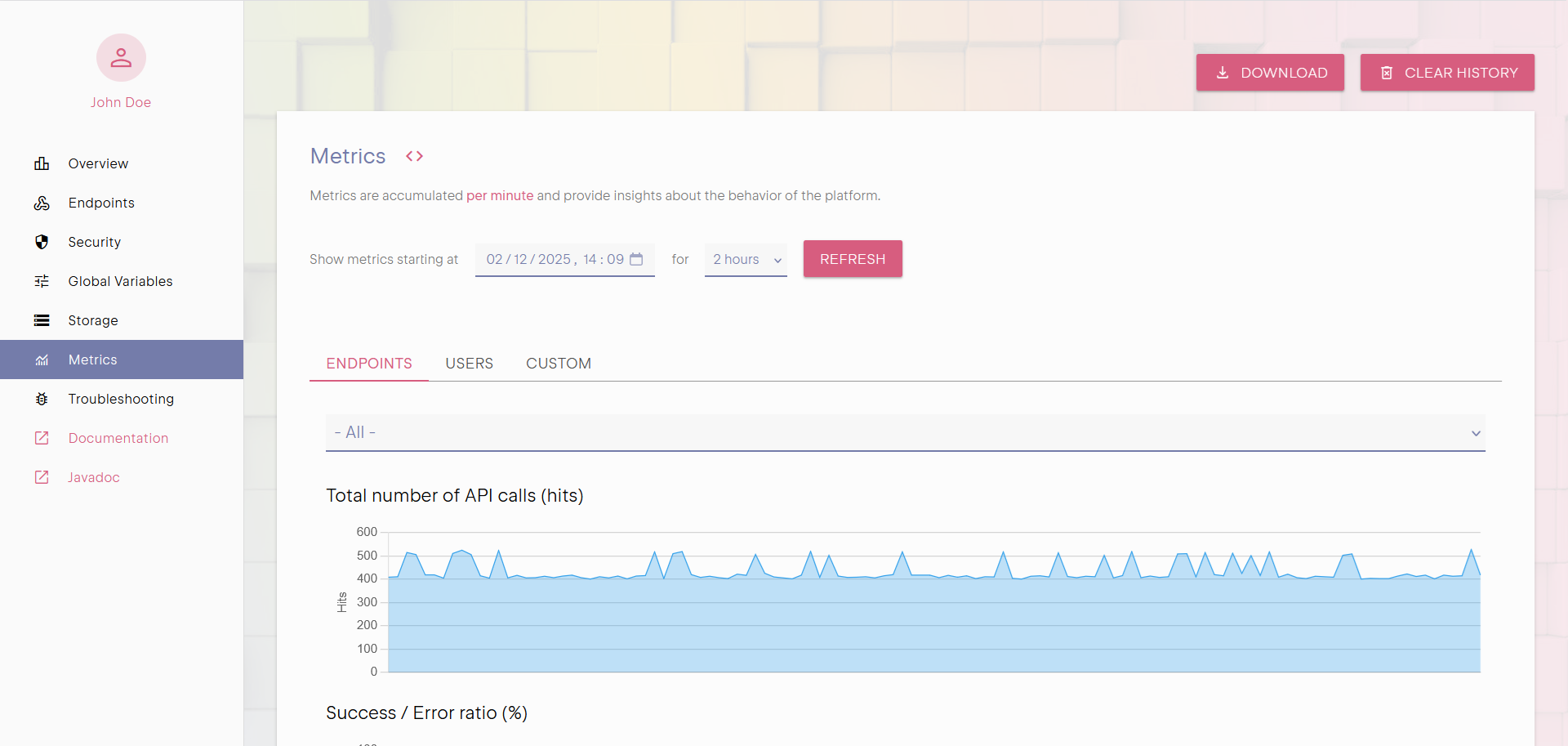
You can query metrics at different point in time and track which endpoints or users experienced issues.
Custom Metrics
Custom metrics in Uniqorn are named counters that automatically track two values:
- The hit count: how many times the metric was updated.
- The aggregated sum: a cumulative value representing a numeric quantity (optional).
These metrics are aggregated and automatically reset every minute, ensuring that values represent short-term trends rather than long-term accumulation.
This rolling behavior is ideal for real-time dashboards and alerting based on recent activity.
To increment the hit count without a value, use:
Api.metrics("custom.metric.name");
If you want to keep track of a quantity beyond a simple count, use:
Api.metrics("checkout.revenue", amount);
Best Practices
- Use clear and consistent names for custom metrics to make interpretation easier across your team.
- Avoid flooding: do not create metrics with dynamic names (e.g.,
metrics("user." + id)), as this leads to unbounded
cardinality and storage issues.
- Keep it lightweight: compute advanced aggregates (e.g., averages, percentiles) and time resolutions externally in your visualization
or analytics layer. Doing this inside the API code can create unnecessary processing overhead and reduce performance.
How-To's
This part of the documentation provides more examples and guidance with the most common operations.
Error Handling
When building an API, proper error handling is essential to ensure meaningful responses to clients.
HTTP response codes indicate whether a request was successful or if an error occurred. Here's a quick recap of relevant status code ranges:
- 2xx (Success): The request was successful (e.g.,
200 OK, 204 No Content).
- 3xx (Redirection): The client must take additional action (e.g.,
301 Moved Permanently).
- 4xx (Client Errors): The request is incorrect or unauthorized (e.g.,
400 Bad Request,
403 Forbidden, 404 Not Found).
- 5xx (Server Errors): The server encountered an error while processing the request (e.g.,
500 Internal Server Error,
503 Service Unavailable).
Unhandled Errors
The API process function allows any exception to be thrown to reduce the boilerplate try/catch code.
If your API method throws an exception and you do not handle it, the framework will automatically return a 500 Internal Server Error,
which is vague and unhelpful. Moreover, it could potentially leak some sensitive information to the caller.
new Api("/api/test", "GET")
.process(data -> {
int result = 10 / 0; // This will cause a division by zero exception
return JSON.object().put("result", result);
});
Response:
HTTP/1.1 500 Internal Server Error
Content-Type: application/json
{
"error": {
"code": 500,
"message": "/ by zero"
}
}
This is not ideal because (1) the client may not get useful information about what went wrong, and (2) it does not differentiate
between a developer mistake and an expected failure.
Controlled Errors
To emit controlled error responses, you should use Api.error(int code, String message) or
Api.error(int code, Data data). These methods will throw a recognized exception, stopping further execution and ensuring
the correct HTTP status code is returned.
new Api("/api/test", "GET")
.process(data -> {
if (data.isNull("name"))
Api.error(400, "Missing name parameter");
return null;
});
Response:
HTTP/1.1 400 Bad Request
Content-Type: application/json
{
"error": {
"code": 400,
"message": "Missing name parameter"
}
}
If you need more control over the returned data, you can use the other variant and supply your own response.
new Api("/api/test", "GET")
.process(data -> {
if (data.isNull("name"))
Api.error(400, JSON.object()
.put("parameter", "name")
.put("cause", "Cannot be null"));
return null;
});
Response:
HTTP/1.1 400 Bad Request
Content-Type: application/json
{
"parameter": "name",
"cause": "Cannot be null"
}
Graceful Handling
The API process function has a failsafe mechanism to return a 500 error in case an exception happens. Although, it is always best to
surround sensitive operations in a try/catch block. This will ensure your API fails gracefully rather than exposing
internal server errors and allows you to control what message the client receives.
new Api("/api/test", "GET")
.process(data -> {
try {
int result = Integer.parseInt(data.get("size")); // Might throw NumberFormatException
} catch (NumberFormatException e) {
Api.error(400, "Invalid number");
}
return null;
});
Environment Parameters
Environment parameters allow users to define global configuration values in the User Panel, making them accessible in code
without hardcoding sensitive or duplicate information. These parameters are read-only in the code, ensuring security and consistency.
If you need read-write global variables, see States & Sharing Data.
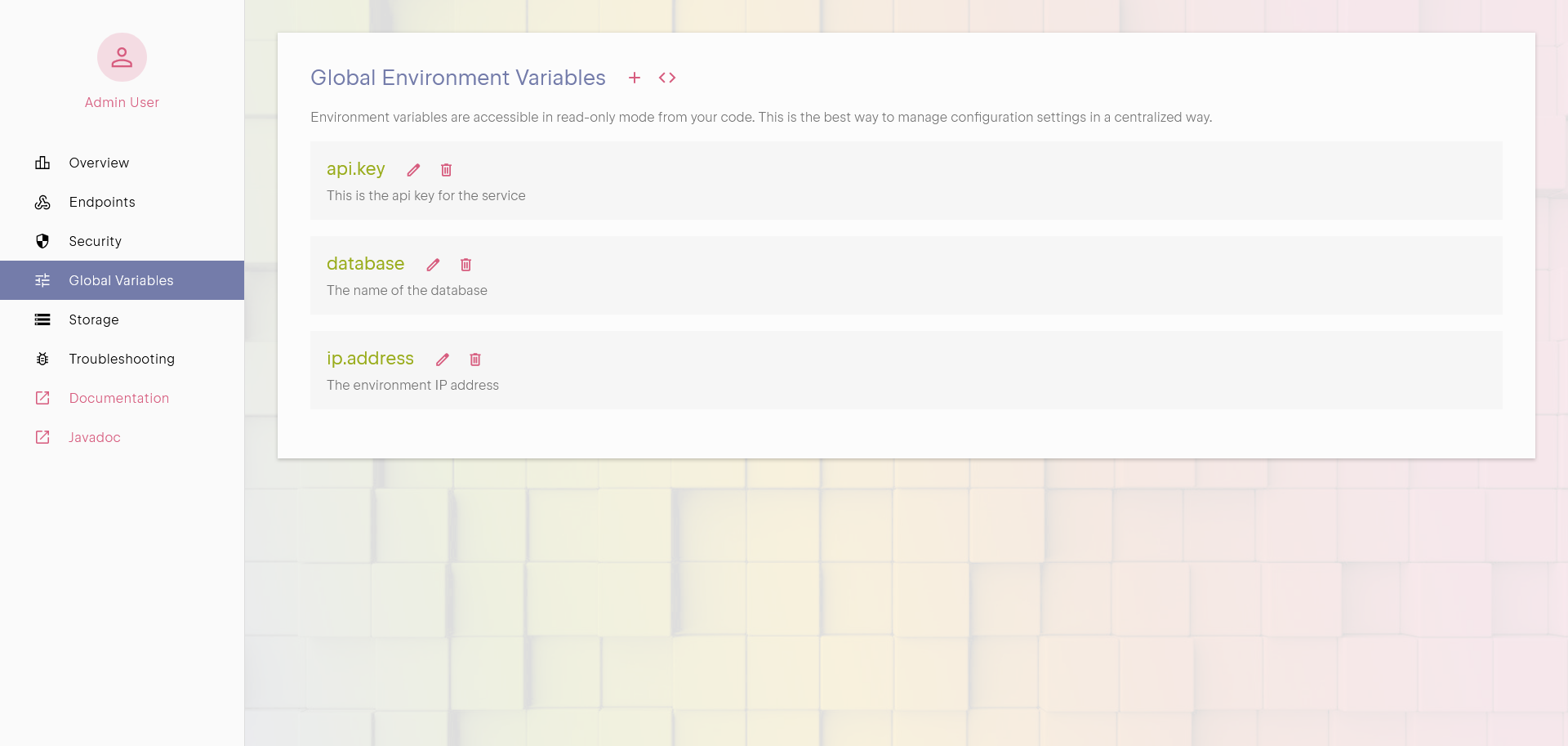
Environment parameters helps improve reusability as values are defined once and reused where needed. When a value needs to change, you
do not have to redeploy your APIs.
new Api("/api/test", "POST")
.process(data -> {
...
String apiKey = Api.env("API_KEY").asString();
...
});
If an environment variable is not set, Api.env() returns an empty data object. You can check if the value is empty using:
Data timeout = Api.env("TIMEOUT");
if (timeout.isEmpty()) { ... }
Parameter Validation
Proper parameter validation ensures that your API only processes valid and expected inputs, preventing unnecessary errors and
improving security. The framework automatically collects and populates declared API parameters while ignoring any extra, unsolicited data.
There is no parameter validation rule by default. If needed, you should supply the validation rule in your code.
How Parameter Validation Works
- You declare required parameters using the
parameter(String name) function.
- You can add a validation predicate as a second argument to enforce constraints.
- If a parameter fails validation, the API does not execute the processing function and instead
returns a
400 Bad Request with a structured error message.
HTTP/1.1 400 Bad Request
Content-Type: application/json
{
"error": {
"code": 400,
"message": "Parameter validation failed for '[parameter-name]'"
}
}
The Input class contains various built-in validation rules that you can apply to your parameters.
Basic Validation
new Api("/api/test", "GET")
.parameter("name", Input.isNotEmpty);
This parameter uses one of the built-in validation rules from the Input class. Check the Javadoc for more possibilities.
Combining Multiple Validations
You can chain multiple predefined validation helpers to enforce stricter rules.
new Api("/api/test", "GET")
.parameter("email", Input.isEmpty.or(Input.isEmail));
In this case, we allow an optional parameter, but if a value is provided, it must be an email address.
Custom Validation
You can provide a custom validation function if the built-in ones are not enough.
new Api("/api/test", "GET")
.parameter("age", age -> age.asNumber() > 18);
This validation method leverages the native JSON type coercion to a numeric value using asNumber() and checks if the value is above 18.
File Upload
Api consumers can upload files to your endpoint using classic multipart/form-data uploads. Files are treated like any other input parameter,
meaning you must declare them explicitly in the parameter list and validate them as file inputs.
new Api("/api/test", "POST")
.parameter("image", Input.isFile);
File Data Structure
When a file is uploaded, it is represented in the data object as a JSON structure:
{
"name": "example.jpg",
"mime": "image/jpeg",
"content": "ÿØÿà..JFIF..."
}
- name: the original file name supplied by the user
- mime: the file's MIME type as it was provided in the request
- content: the binary content (stored as a string)
Since the file's content is stored as a binary string, you must convert it into raw bytes for further processing:
byte[] content = file.asString("content").getBytes(StandardCharsets.ISO_8859_1);
Using any other charset may alter the binary data and corrupt the uploaded file.
Always use ISO-8859-1 to ensure the bytes remain intact.
Files are loaded directly into memory as JSON structures and are not offloaded to disk.
This means that file uploads are limited by available RAM. Larger files will be rejected by the system automatically.
Processing File Uploads
In the API process function, you can process it like a JSON object. Do not forget to enforce parameter validation:
new Api("/api/test", "POST")
.parameter("image", Input.isFile
.and(Input.hasFileExtension(".jpg"))
.and(Input.hasMimeType("image/jpeg"))
.and(Input.maxSize(512000)))
.process(data -> {
byte[] jpg = data.get("image").asString("content").getBytes(StandardCharsets.ISO_8859_1);
...
});
File Download
By default, Uniqorn APIs work with JSON data, a flexible and widely used format. However, there are cases where you need to return files instead
of JSON, such as XML documents, ZIP archives, PDFs, or images.
To achieve this, Uniqorn uses a special JSON response format to use in your APIs that instructs the system to handle the response as a file:
{
"isHttpResponse": true,
"code": 200,
"headers": {},
"mime": "application/xml",
"body": "<tag>>value</tag>"
}
- isHttpResponse: Marks the response as an HTTP response override.
- code: Specifies the HTTP status code (optional).
- headers: Allows custom response headers (optional).
- mime: Defines the file's MIME type (equivalent to setting the
Content-Type header).
- body: Contains the actual file content.
When sending binary files, you need to convert the content to a binary-safe string using ISO-8859-1
encoding. This prevents corruption when transmitting raw bytes.
new Api("/api/test", "GET")
.process(data -> {
byte[] pdf = ...; // Your binary file content
return JSON.object()
.put("isHttpResponse", true)
.put("mime", "application/pdf")
.put("body", new String(pdf, StandardCharsets.ISO_8859_1));
});
Http Fetch
Uniqorn provides a simple and efficient way to make HTTP requests using the Http class. You can use it to send or fetch
data from remote endpoints effortlessly.
There are two main methods:
- get(): Used for retrieving data without a request body.
- post(): Used for sending data in the request body.
Both methods support optional overloads for sending additional data parameters, specifying custom headers, choosing a specific HTTP method,
and defining a timeout (in milliseconds).
Http.get(String url);
Http.get(String url, Data queryString);
Http.get(String url, Data queryString, Data headers);
Http.get(String url, Data queryString, Data headers, String method);
Http.get(String url, Data queryString, Data headers, String method, int timeout);
Http.post(String url);
Http.post(String url, Data body);
Http.post(String url, Data body, Data headers);
Http.post(String url, Data body, Data headers, String method);
Http.post(String url, Data body, Data headers, String method, int timeout);
Handling Responses and Errors
If the HTTP call succeeds, the response is returned as a JSON string object. If the response MIME type is application/json,
it is automatically parsed into a full JSON object.
If the request fails with an HTTP status ≥400, an Http.Error is thrown, containing both the status code and response
body.
If the call fails due to connectivity issues or other causes, a runtime exception is thrown.
The most basic example is:
Data response = Http.get("https://api.example.com/data");
System.out.println(response.asString());
The response headers are not available when using the Http class. We focus on the content itself.
If the response is advertized as JSON format, it will be automatically parsed into a Data object. Otherwise it will be a simple string.
An example of a request with proper error handling is as follows:
try {
Data response = Http.post("https://api.example.com/data",
JSON.object().put("amount", 42), // the data to send
JSON.object().put("Authorization", "Bearer my-token"), // additional headers
"PUT", // http method
5000 // timeout
);
}
catch (Http.Error error) { ... }
catch (Exception other) { ... }
Note that the Http class is synchronous and will wait for completion. This is because the context of your API is
already asynchronous, so there is no added value to complicate things further. However, if you absolutely need an asynchronous behavior,
you can trigger a Background Operation.
If you want to upload a file to the remote endpoint, you can use the same JSON file structure as for a File Upload
and specify a Content-Type: multipart/form-data header.
Data response = Http.post("https://api.example.com/data",
JSON.object().put("image", JSON.object()
.put("name", "picture.jpg")
.put("mime", "image/jpeg")
.put("content", ...)),
JSON.object().put("Content-Type", "multipart/form-data")
);
Storage
In Uniqorn, a storage is a built-in abstraction over an object store that provides a familiar file-system-like interface.
It allows APIs to read and write persistent data using a classic directory and file structure.
This is useful for storing structured or unstructured data that needs to survive across deployments, restarts, or scaling operations.
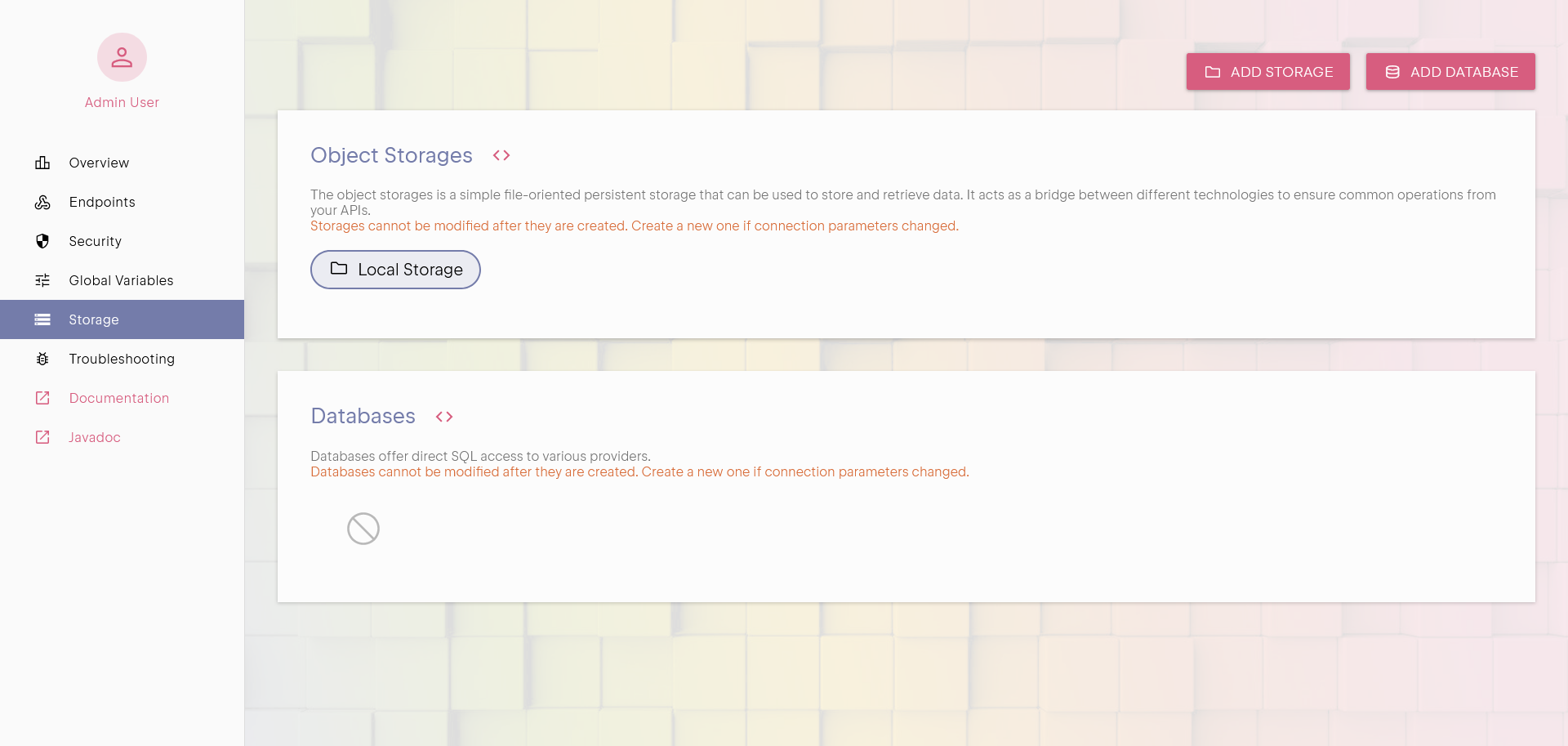
Storage support both direct mapping to data structures, and pure binary data (images,...)
Storage is not thread safe. You should handle concurrent write operations using a synchronized block, or an
atomic operation.
Connecting a Storage
Before using a storage in your API code, it must be defined and connected through the User Panel.
Compatible providers may be added over time.
Once configured, it becomes available by name within your code:
Storage.Type store = Api.storage("my-storage");
The default Local Storage is always available to store data closest to your instance.
Operations
The storage interface offers a few straightforward operations to get(path), put(path, content), or
remove(path) content. You can check the Javadoc for more details.
For convenience, if you are dealing with structured data, you can store and fetch Data structures directly:
Api.storage("my-storage")
.put("/path/to/file", JSON.object().put("key", "value"));
Data content = Api.storage("my-storage").getData("/path/to/file");
Listing Storage Entries
To explore stored files, you can use the tree(path) method to view the immediate contents of a folder (useful to build a tree view),
or the list(path) method to retrieve the entire nested structure recursively.
However, it's important to understand that pagination is not supported in these methods.
The storage interface is intentionally minimal and consistent across backends, and pagination is highly implementation-specific.
If the underlying system offers pagination, only the first page is returned by default. This design choice favors simplicity and determinism.
If a directory contains a large number of entries, the system will return as many as it can,
but there is no guarantee beyond that.
If you're finding that a single directory is becoming overloaded with too many entries, it's often a sign that the data should be better
organized, either split into subfolders or compiled in an index-file that contains the exhaustive list of entries.
The limitation is not just technical, but conceptual: storage is optimized for clarity and manageability.
When to Use Persistent Storage
Use storage when you need to retain files or data across deployments or reboots. Storage is ideal when you need to read or write data using
a known identifier (typically a path) without needing to search or filter the content. The access pattern is direct: you put some content
at a path and later retrieve it from the same path.
If, on the other hand, your use case involves searching based on the content of the data, such as querying for all entries matching a
condition or filtering by fields, then a Database is more appropriate.
If data does not need to survive a reboot, you can use States which is best for short-lived, memory-resident data.
Database Query
In Uniqorn, the Database interface provides an abstraction over a traditional relational database, giving your API code direct access to
query structured data using plain SQL. It is designed to be simple, robust, and easily integrated into your application logic without the
need for complex ORM layers.
Before using a database in your API code, it must be defined and connected through the User Panel.
Compatible providers may be added over time.
Once configured, it becomes available by name within your code:
Database.Type db = Api.database("my-database");
The system handles connection pooling automatically and ensures that reconnections are managed transparently,
even in case of dropped or expired connections.
The default Local Database is always available to store data closest to your instance.
Executing Queries
The most straightforward way to perform a query is:
Data rows = Api.database("my-database")
.query("SELECT * FROM table WHERE field = ?", value);
for (Data row : rows) {
long id = row.asLong("id");
...
}
- Queries are written in plain SQL, this gives you the uttermost flexibility, but comes with tradeoffs regarding vendor-specific
subtleties.
- Parameters are passed separately to prevent SQL injection.
- The result is returned as a Data object, typically an array of rows, each represented as a map of key/value pairs. All matching
records are returned at once, no cursor or pagination is implemented at the interface level. If your query returns too many rows,
it may cause memory pressure, so it's recommended to use
LIMIT or filters appropriately.
Always use parameterized queries. Injecting parameters directly into the SQL string is not safe and can
expose your API to SQL injection attacks.
Detailed query options and other metadata discovery methods are present in the Javadoc.
Transactions
When several requests need to be grouped and committed atomically (all or nothing), then you should use a transaction.
The queries are the same, but executed within one block. If there is no error, the transaction is committed. If there is
an error, it is rolled back.
Api.database("my-database").transaction(tx -> {
for( int i = 0; i < 10; i++ )
tx.query(...);
});
When to Use a Database
Use a database when you need to retain structured data across deployments or reboots. Databases are ideal when you need to query for
all entries matching a condition or filtering by fields.
If, on the other hand, your use case involves storing and fetching data based on a simple identifier,
maybe a Storage is more appropriate.
If data does not need to survive a reboot, you can use States which is best for short-lived, memory-resident data.
States & Sharing Data
When building APIs, you may need to share data between successive calls to the same endpoint or across different endpoints.
While you can always use persistent Storage (database, file system, etc.), Uniqorn provides in-memory state sharing for
temporary data storage.
Local vs. Global State
Uniqorn offers two types of transient storage:
- Local state via
State.local(). Data stored here is only accessible within the same API.
- Global state via
State.global(). Shared across all APIs in the instance.
These states are transient, they do not persist beyond the lifecycle of the instance.
If you need to store data permanently, use a database or other storage.
Using Local and Global States
Local state is useful when an endpoint needs to store values that are specific to its execution but don't need to be shared with other APIs.
Global state allows APIs to share data across endpoints.
You can eventually scope the state for a specific user, and set an automatic expiration time.
new Api("/api/test", "GET")
.process((data, user) -> {
// set a local state for the user with an expiration time of 5s
State.local("key", user, "value", 5000);
// set a global state not bound to any user, and does not expire
State.global("key", "value");
return JSON.object()
.put("local-per-user", State.local("key", user))
.put("global", State.global("common"));
});
You can store any object type in the state. When fetching the value, the result is auto-casted
to the receiving type. If it does not match, it will throw an exception.
State.local("key", 42); // the value type is an integer
int value = State.local("key"); // auto-casting to int
String value2 = State.local("key"); // throws a ClassCastException
State.local("key", "fourty-two"); // overwrite the value with a different type
Be careful when storing or modifying states because multiple modifications may happen at the same time.
Have a look at Atomic Operations for more info.
Chain Endpoints
In certain cases, it's useful to call (or relay to) another API endpoint without performing a full HTTP roundtrip.
Instead of making an external HTTP request, Uniqorn allows you to internally chain endpoints using the Api.chain() method.
Why use endpoint chaining?
- Avoid extra network overhead: Calls remain within the application.
- Reuse existing logic: No need to duplicate endpoint functionality.
- Improve modularity: Split logic into smaller, maintainable endpoints.
- Group atomic operations: Combine multiple calls into one request.
Caution, if you chain endpoints, it becomes difficult to implement a rollback mechanism. Always check if there are side effects
or consequences when one of the chained calls fails.
The Api.chain() method allows you to call an internal API endpoint as if it were a function. The result is returned as a Data object.
new Api("/api/relay", "GET")
.process(data -> {
return Api.chain("/api/target");
});
By default, a chained call runs as the same user who called the current endpoint: the target endpoint's
access rules are enforced exactly as if that user had reached it directly. If you need to specify input parameters, or to
run the target as a different user, use one of the overloads to fine-tune the target API call.
The four-argument overload Api.chain(url, method, data, user) lets you choose the user the target runs as.
Passing User.SYSTEM bypasses every access check on the target endpoint, so use it only when you
deliberately want that escalation. Pass User.ANONYMOUS to drop privileges instead.
Example using chaining for aggregation of data:
new Api("/api/user-profile", "GET")
.parameter("userId")
.process(data -> {
Data user = Api.chain("/api/user", "GET", data);
Data settings = Api.chain("/api/settings", "GET", data);
return JSON.object()
.put("user", user)
.put("settings", settings);
});
The target endpoint does not know if it is chained or called normally, be sure to use try...catch to handle exceptions.
Atomic Operations
When working with shared data, concurrency can lead to race conditions, causing inconsistent or lost updates. One way to solve this problem is
to use .concurrency(1) but this applies to the entire API. To ensure atomicity on selected operations, Uniqorn provides
an easy-to-use method:
Api.atomic(() -> { /* Your code here */ });
This ensures that only one atomic block runs at a time, preventing conflicts in shared data or operations.
When to Use Atomic Execution?
Without atomic execution, multiple concurrent requests could modify shared data incorrectly. Consider this non-atomic counter update:
new Api("/api/increment", "POST")
.process(data -> {
int count = State.global("counter");
// <-- concurrency issue here
State.global("counter", count + 1);
return JSON.object().put("counter", count);
});
If two requests execute at the same time, both might read the same initial value, leading to lost updates. In this case you could use an
AtomicInteger but it may not be so easy in all cases.
To make sure operations execute sequentially, wrap them in Api.atomic():
new Api("/api/increment", "POST")
.process(data -> {
...
int counter = Api.atomic(() -> {
int count = State.global("counter");
State.global("counter", count + 1);
return count;
});
return JSON.object().put("counter", counter);
});
Note that the Api.atomic() method may return a value, or not depending on your needs.
When Not to Use Atomic Execution?
Atomic operations have an overhead cost in terms of processing power and lock out all other API from your instance so you can
safely use States & Sharing Data. This is a strong bottleneck if not managed carefully.
If you are reading a value without modifying it, or if you are performing independent operations, then you should avoid using
the atomic operations.
Background Operations
When building an API, there are situations where a request triggers an operation that doesn't need to complete before returning a response.
For example, logging user activity, sending an email, or processing a large dataset might take a few seconds, but the client doesn't need to
wait for these tasks to finish.
To handle these cases, Uniqorn provides a simple way to defer tasks using Api.defer().
This allows you to run background operations without blocking the API response, ensuring a smoother user experience and preventing unnecessary delays.
Using Background Tasks
The Api.defer() method accepts a block of code that should be executed asynchronously.
Unlike a normal method call, which runs immediately and returns a result, a deferred task is scheduled for execution in the background,
and the main API code proceeds without waiting for the completion of the background task.
This approach is useful when you need to:
- Perform a non-urgent operation (e.g., logging, analytics, sending notifications).
- Improve response time by offloading heavy tasks.
- Avoid request timeouts caused by long-running operations.
For example, this simple API endpoint sends a notification to users. Instead of making the client wait until the email is sent,
we defer the operation:
new Api("/api/notify", "POST")
.parameter("email", Input.isEmail)
.parameter("text", Input.isNotEmpty)
.process(data -> {
// send the email in the background
Api.defer(() -> {
sendEmail(data.get("email"), data.get("text"));
});
// the response is sent immediately
return JSON.object().put("success", true);
});
With this approach, the API immediately completes while the actual email is sent asynchronously. The client never experiences a delay,
even if sending the email takes a few seconds.
Passing Data to Deferred Tasks
Deferred tasks run in a different execution context from the request, so State.local() does not resolve to the
calling endpoint there and should not be used inside a deferred task.
For example, this would not work as expected:
new Api("/api/test", "GET")
.process(data -> {
Api.defer(() -> {
String userId = State.local("userId"); // this will not work
doSomething(userId);
});
return null;
});
Instead, always pass necessary data explicitly when deferring tasks:
new Api("/api/test", "GET")
.process(data -> {
String userId = State.local("userId");
Api.defer(() -> {
doSomething(userId); // works correctly
});
return null;
});
Handling Errors
Since deferred operations run independently of the API request, any errors they produce will not be sent back to the client.
If an exception occurs inside a background task and isn't handled, it will fail silently.
If you need to handle failures, be sure to wrap deferred operations in a try-catch block:
Api.defer(() -> {
try {
doSomething();
} catch(Exception e) {
handleError();
}
});
When Not to Use Background Tasks
While deferring operations can significantly improve API responsiveness, there are situations where using a background task may
be inappropriate or even counterproductive.
- When you need the task to complete before responding:
new Api("/api/checkout", "POST")
.process(data -> {
Api.defer(() -> processPayment(data)); // Dangerous: no confirmation
return "Payment request received.";
});
- When you need immediate feedback on success or failure, such as operations that will perform a validation against input data,
checking credentials or other verifications:
new Api("/api/signup", "POST")
.parameter("email")
.process(data -> {
Api.defer(() -> {
String email = data.asString("email");
if (checkIfValid(email)) // Dangerous: check email before
sendEmail(email);
});
return "Signup email sent.";
});
- When you expect strict execution order, since background tasks are asynchronous, you have no guarantee about their execution order:
new Api("/api/test", "GET")
.process(data -> {
Api.defer(() -> stepOne());
Api.defer(() -> stepTwo()); // Might execute before stepOne()
return "Steps scheduled.";
});
- When the deferred task is computationally expensive and may stack up on the server:
new Api("/api/test", "GET")
.process(data -> {
Api.defer(() -> veryLongIntensiveTask());
return "Process started.";
});
Deferring operations is a powerful technique, but it is not a shortcut to infinite scalability. While background tasks create the
impression of an immediate response, they still run on the same server and contribute to its overall workload. If heavily used, background
processing will affect other API requests, lead to resource starvation, or introduce uncontrolled growth if tasks pile up faster than they
are processed.
Scheduling a task in the background is inherently heavier than running it directly, so you should consider acceptable response time
and balance it with the need for a background task.
new Api("/api/test", "GET")
.process(data -> {
Api.defer(() -> veryQuickTask()); // Overkill for a quick operation
return "Process started.";
});